# 저작권 문제때문에 공유하거나 배포하지는 않습니다.
평소 사전에 관심이 좀 있다보니 스타딕트용이나 Mdit용 사전 자료를 직접 만들거나 인터넷으로 구해서 사용했다. 직접 만들었다고 해도 원시 자료를 이용해 사전 제작 프로그램과 문서 편집 프로그램으로 만드는 비교적 간단한 작업이었다.
표준국어대사전도 스다틱트 또는 Mdict용으로 이미 만들어진 자료나 하다못해 원시 자료로도 구하려고 노력했으나 저작권문제 때문에 도저히 구할 수가 없어서 직접 클리핑해 제작해보기로 했다.
클리핑은 '카오스'라는 분이 만든 설명서 '웹사전 클리핑으로 표준국어대사전 만들기.exe'를 참고했다. 클리핑 소스는 '도아의 세상사는 이야기'라는 블로그에 올려놓은 클리핑 소스를 카오스님이 약간 수정한 것이었다. 어쨌든 아주 자세히 설명되어 있어서 비교적 쉽게 클리핑을 할 수가 있었다.
혹시 필요하신 분은 받으세요.
 웹사전_클리핑으로_표준국어대사전_만들기.exe
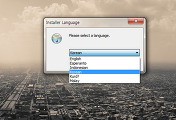
웹사전_클리핑으로_표준국어대사전_만들기.exe표준국어대사전은 총 표제어수가 51만개 넘는 방대한 양을 자랑한다. 그래서 5만개 단위씩 끊어서 총 11개의 클리핑 소스로 나누어 작업을 시행했다. 그림에는 9개밖에 보이지 않는데 실제로는 11개의 도스창을 띄어 사전 자료를 국립국어원에서 받았다. 11개창을 동시에 띄워 사전 자료를 다 받는데 걸린 시간은 대략 28시간 정도였다. 좀 더 빨리 받을 수 있었으나 거의 다 받았을 무렵 끊겨버려 클리핑 소스를 수정해 끊긴 부분부터 이어받느라 시간이 더 걸렸다. 받는데 걸리는 시간은 서버 상태, 인터넷 속도, 시간대 등에 따라 약간씩 다른 것 같다. 더 빨리 받고 싶다면 2-3만개 단위로 클리핑 소스를 만들어 창을 동시에 18-26개 정도로 띄우면 될 것이다. 도스창으로 받는 거라서 그런지 창을 많이 띄운다해도 컴퓨터에 큰 무리가 가지는 않는 것 같다.

클리핑 소스를 실행한 폴더에 그림 파일, 사전 자료 등이 내려받기된다.

이렇게 나눠받은 사전 자료와 그림 자료를 한 군데 모아서 사전 자료는 하나의 txt 파일로 통합해줘야한다. 통합한 표준국어대사전 원시 자료 파일은 ksd orginal.txt인데 용량이 무려 383Mb를 넘는다. 가장 아래의 '표준국어대사전.txt'는 원시 자료 파일을 수정한 것이다. 이 파일을 스다틱트용으로 변환해 구루딕(Gurudic)등의 스타딕트 사전에 넣으면 표준국어대사전이 내 손에 들어오는 것이다.

아래는 스다딕트용으로 변환한 것이다. res폴더에 그림 파일들이 들어가 있고, '표준국어대사전.dict.dz'는 사전 자료들이 포함된 파일이며, '표준국어대사전.idx'는 표제어 정리된 파일, ''표준국어대사전.ifo'는 이 사전의 정보를 담고 있는 파일이다.

#그림 표기#
이렇게 만든 사전의 장점은 그림도 함께 보여준다는 것이다. 무려 9천여장 이상의 그림이 수록되어 있다.
| |
|


| |
|


#최근 개정된 표준어#
최근에 표준어 개정으로 '짜장면', '허접쓰레기' 등도 표준어로 등재되었다. 그래서 예전 사전에는 '짜장면'을 찾으면 ''자장면'의 잘못'으로 표기되어있지만 이번에 클리핑한 사전에는 '=자장면'이라고 되어있다.
| |
|


'허접쓰레기'도 마찬가지로 '허섭스레기'와 함께 표준어가 되었다.
| |
|


#풍부한 관용구 및 속담#
관용구/속담도 아주 풍부하게 수록되어있다. '관용', '속담'이라는 아이콘이 옆에 표시되어있어 쉽게 알아볼 수 있다.
| |
|


#개정 전에 비해 출처 표기는 미흡#
그렇다고 예전 사전보다 더 좋아진 건 아닌 것 같은게 예전 사전이 고문서에 대한 년도 및 명칭이 더 자세하게 나와았다. 왼쪽이 글쓴이가 클리핑한 최신 자료이며 오른 쪽이 예전 자료이다.
| |
|


#풍부한 동음이의어 수록#
표준국어대사전답게 동음이의어도 풍부하게 수록되어있는데 '사'는 무려 45개, '기'는 44개로 나뉘어 뜻풀이가 설명되어있다.
| |
|


#풍부한 인명 사전 기능#
혹시나싶어 러시아 작가 '이반 부닌'과 '미하일 숄로호프'를 찾아봤더니 역시나 수록되어있다. 부닌은 없을 거라고 생각했는데 수록되어있어서 놀라웠다.
| |
|


#풍부한 공식 수록#
여러 수학, 물리, 화학 공식 등도 수록되어있는데 공식들은 사실 그림으로 표기되어있다. 하지만 이 사전에는 표기되어있지 않다. 왜냐하면 그림들이 'img src'로 연결되어있는데 반해 이 공식 등은 'formula.jsp'로 연결되어있어서 클리핑이 제대로 되지않았기 때문이다. 원래 표제어만 표기되고 아무 것도 나오지 않았는데 하나하나 수정했다. 하지만 공식 그림까지 수정하려니 너무 시간이 걸려서 뜻풀이글만 수정했다.
| |
|


#북한어 수록#
북한어도 역시 수록되어있다.
| |
|


이번에 클리핑해서 만든 표준국어대사전은 총 표제어수가 510,216개이다. 이 표제어수도 클리핑하는 사람마다 조금씩 다른 걸로 봐서 누락된 표제어들이 꽤 있을 것이다. 저작권 문제 때문에 공유 및 배포하지는 않을 것이다.

클리핑 작업도 작업이지만 원시 자료를 수정하는 작업이 만만치가 않았다.
어느 정도 수정하기는 했지만 국립국어원 누리집에서 찾아보는 것 만큼 완벽하지는 않다. 특히 옛글과 한자 같은 경우는 제대로 클리핑되는 경우도 많았지만, 글자가 깨지는 경우도 꽤 많았다. 이걸 하나하나 수정하기엔 너무 많은 시간이 필요하거니와 옛글을 찾아볼 일도 거의 없어 몇 개만 수정하고 그만두었다. 또 구루딕에서는 옛글 글꼴을 지원하지 않아 옛글을 볼 수가 없다. 그리고 누리 글꼴(Web font)도 마찬가지로 지원하지 않는다.
예문은 글자색이 뜻풀이와 똑같이 검은색이어서 구분이 잘 안 돼 회색으로 바꿨다. 또 예문 표시 특수 기호 색깔도 녹색으로 수정했다. 관용 및 속담 아이콘도 표시가 되지 않아 수정했으며 관용 및 속담의 예문은 다음 줄에 표기되지 않고 이어서 적혀있어 다음 줄로 표기되도록 수정했다. 이 이외에도 내림차순 정리도 해줬다.
국립국어원 누리집 자체의 소스에 그림 파일 연결 경로가 잘못된 것들도 좀 있어서 사전에서 제대로 그림이 뜨게 하려면 직접 경로를 수정해줘야한다.
들인 시간과 노력은 길고 험난했지만 그래도 내 손으로 직접 만들어보니 그 성취감은 꽤 크다.
※ 표준국어대사전 자체에 대한 비판도 많은 모양이다. 수많은 학자들이 엄청난 예산을 들여 제작한 사전임에도 불구하고 순우리말, 각 지역어 등보다 중국식 한자어, 일본식 한자어 및 일본어, 외국어 및 외래어 등의 수록에 더 치중했다는 비판이 그것이다. 개인적으로 우리말과 각 지역어 사용에 관심이 많다보니 상당히 아쉬운 점이다. 우리말을 보존하고 기록해야할 국립국어원에서 오히려 우리말을 홀대하고 있다는 것은 큰 모순이 아닐 수 없다.
또 개정 작업이 이루어질 것이다. 그때는 표준국어대사전에 어울리는 않는 표제어들은 삭제하고 제대로된 우리말 사전이 될 수 있도록 우리말을 더욱 발굴해 수록하였으면 한다. 단순히 표제어의 양 늘리기보다 각 지역과 시대에 따라 사용되어 온 그리고 사용되고 있는 진짜 우리말을 더 실었으면 한다.
'Other Stories > Science/IT' 카테고리의 다른 글
| 삼성은 애플의 적이 아니라 열렬한 팬이다? (78) | 2012.08.27 |
|---|---|
| DSLR 사진기 및 렌즈 별명 정리 (2) | 2012.02.11 |
| 골든딕트(GoldenDict)사전에 러시아어사전 설치하기 (21) | 2011.09.21 |
| 아이폰 4 재밌는 12가지 잡는 방법 (2) | 2010.07.05 |
| 북한 OS "붉은별" 자세히보기(원문 번역) (99) | 2010.03.03 |